 "
"
Team:TU Darmstadt/modelling/Structure
From 2013.igem.org
| (10 intermediate revisions not shown) | |||
| Line 112: | Line 112: | ||
| + | LI.list1 {list-style: disc; color:white;} | ||
| + | .blacktext {color:black} | ||
| + | p, ul { | ||
| + | padding: 0; | ||
| + | margin: 0; | ||
| + | } | ||
dl.igemTUD2013gelpicture | dl.igemTUD2013gelpicture | ||
| Line 155: | Line 161: | ||
dl.igemTUD2013gelpicture2 | dl.igemTUD2013gelpicture2 | ||
{ | { | ||
| - | border: | + | border: 0px solid transparent; |
| - | background-color: | + | background-color: transparent; |
| - | width: | + | width: 400px; |
text-align: center; | text-align: center; | ||
padding: 5px 5px 5px 5px; | padding: 5px 5px 5px 5px; | ||
| Line 168: | Line 174: | ||
{ | { | ||
font-weight: bold; | font-weight: bold; | ||
| - | background-color: | + | background-color: transparent; |
color: #959289; | color: #959289; | ||
padding: 0 0; | padding: 0 0; | ||
| Line 176: | Line 182: | ||
.igemTUD2013gelpicture2 dd img | .igemTUD2013gelpicture2 dd img | ||
{ | { | ||
| - | border: | + | border: 0px solid transparent; |
| - | width: | + | width: 400px; |
| - | height: | + | height: 216px; |
} | } | ||
| Line 271: | Line 277: | ||
<font size="3" color="#F0F8FF" face="Arial regular"> | <font size="3" color="#F0F8FF" face="Arial regular"> | ||
<p text-aligne:left style="margin-left:50px; margin-right:50px"> | <p text-aligne:left style="margin-left:50px; margin-right:50px"> | ||
| - | While our proteins are functionally described in literature and during the IGEM competition, only part of the structures are available in the protein data bank. For further work and visualizations, protein structures are indispensable. We used Yasara Structure [1] to calculate 3-dimensional structures of all of our proteins for the IGEM. | + | While our proteins are functionally described in literature and during the IGEM competition, only part of the structures are available in the protein data bank. For further work and visualizations, protein structures are indispensable. We used Yasara Structure <span style="color:blue"><sup>[1]</sup></span> to calculate 3-dimensional structures of all of our proteins for the IGEM. |
| Line 292: | Line 298: | ||
<font size="3" color="#F0F8FF" face="Arial regular"> | <font size="3" color="#F0F8FF" face="Arial regular"> | ||
<p text-aligne:left style="margin-left:50px; margin-right:50px" align="left"> | <p text-aligne:left style="margin-left:50px; margin-right:50px" align="left"> | ||
| - | Description how our Yasara script calculates homology model[7]:<br> | + | Description how our Yasara script calculates homology model<span style="color:blue"><sup>[7]</sup></span>:<br> |
| - | + | ||
| - | + | <dl class="igemTUD2013gelpicture2" style="margin-right:50px;"> | |
| + | <dd><img alt="DKL" src="https://static.igem.org/mediawiki/2012/5/5e/Aln%2BpnB.png" width="150%" height="150%" align="right"style="margin-left:50px"; "margin-right:50px"></dd> | ||
| + | </dl> | ||
| + | <!-- | ||
<img alt="DKL" src="https://static.igem.org/mediawiki/2012/5/5e/Aln%2BpnB.png" width="400" height="216,5" align="right"> | <img alt="DKL" src="https://static.igem.org/mediawiki/2012/5/5e/Aln%2BpnB.png" width="400" height="216,5" align="right"> | ||
| - | + | --> | |
<ol style="margin-left:50px; margin-right:50px; text-align:justify; "> | <ol style="margin-left:50px; margin-right:50px; text-align:justify; "> | ||
| - | <li>Sequence is PSI-BLASTed against Uniprot [2]</li> | + | <li>Sequence is PSI-BLASTed against Uniprot <span style="color:blue"><sup>[2]</sup></span></li> |
<li>Calculation of a position-specific scoring matrix (PSSM) from related sequences</li> | <li>Calculation of a position-specific scoring matrix (PSSM) from related sequences</li> | ||
<li>Using the PSSM to search the PDB for potential modeling templates</li> | <li>Using the PSSM to search the PDB for potential modeling templates</li> | ||
| - | <li>The Templates are ranked based on the alignment score and the structural quality[3]</li> | + | <li>The Templates are ranked based on the alignment score and the structural quality<span style="color:blue"><sup>[3]</sup></span></li> |
| - | <li>Deriving additional information’s for template and target (prediction of secondary structure, structure-based alignment correction by using SSALN scoring matrices [4]).</li> | + | <li>Deriving additional information’s for template and target (prediction of secondary structure, structure-based alignment correction by using SSALN scoring matrices <span style="color:blue"><sup>[4]</sup></span>).</li> |
| - | <li>A graph of the side-chain rotamer network is built, dead-end elimination is used to find an initial rotamer solution in the context of a simple repulsive energy function [5]</li> | + | <li>A graph of the side-chain rotamer network is built, dead-end elimination is used to find an initial rotamer solution in the context of a simple repulsive energy function <span style="color:blue"><sup>[5]</sup></span></li> |
<li>The loop-network is optimized using a high amount of different orientations</li> | <li>The loop-network is optimized using a high amount of different orientations</li> | ||
<li>Side-chain rotamers are fine-tuned considering electrostatic and knowledge-based packing interactions as well as solvation effects.</li> | <li>Side-chain rotamers are fine-tuned considering electrostatic and knowledge-based packing interactions as well as solvation effects.</li> | ||
| - | <li>An unrestrained high-resolution refinement with explicit solvent molecules is run, using the latest knowledge-based force fields[6].</li> | + | <li>An unrestrained high-resolution refinement with explicit solvent molecules is run, using the latest knowledge-based force fields<span style="color:blue"><sup>[6]</Sup></span>.</li> |
</ol> | </ol> | ||
| Line 325: | Line 334: | ||
<font size="3" color="#F0F8FF" face="Arial regular"> | <font size="3" color="#F0F8FF" face="Arial regular"> | ||
<p text-aligne:left style="margin-left:50px; margin-right:50px"> | <p text-aligne:left style="margin-left:50px; margin-right:50px"> | ||
| - | All these steps are performed to every template used for the modeling approach. For our project we set the maximum amount of templates to 20. Every derived structure is evaluated using an average per-residue quality Z-scores. At last a hybrid model is built containing the best regions of all predictions. This procedure make prediction’s accurate and thus more realistic. For the evaluation we used the Yasara Z-scores.A Z-score describes how many standard deviations the model quality is away from the average high-resolution X-ray structure. Negative values indicate that the homology model looks worse than a high-resolution X-ray structure. The overall Z-scores for all models have been calculated as the weighted averages of the individual Z-scores using the formula Overall = 0.145*Dihedrals + 0.390*Packing1D + 0.465*Packing3D [7]. | + | All these steps are performed to every template used for the modeling approach. For our project we set the maximum amount of templates to 20. Every derived structure is evaluated using an average per-residue quality Z-scores. At last a hybrid model is built containing the best regions of all predictions. This procedure make prediction’s accurate and thus more realistic. For the evaluation we used the Yasara Z-scores.A Z-score describes how many standard deviations the model quality is away from the average high-resolution X-ray structure. Negative values indicate that the homology model looks worse than a high-resolution X-ray structure. The overall Z-scores for all models have been calculated as the weighted averages of the individual Z-scores using the formula Overall = 0.145*Dihedrals + 0.390*Packing1D + 0.465*Packing3D <span style="color:blue"><sup>[7]</sup></span>. |
<br> | <br> | ||
| Line 337: | Line 346: | ||
We used the Yasara script hm_build.mcr for the model creation with the following parameters: | We used the Yasara script hm_build.mcr for the model creation with the following parameters: | ||
<ul style="margin-left:50px; margin-right:50px; text-align:justify; "> | <ul style="margin-left:50px; margin-right:50px; text-align:justify; "> | ||
| - | <dl class="li" style="margin-right:50px;"> Modeling speed (slow = best): Slow</dl> | + | <dl class="li" style="margin-right:50px;">- Modeling speed (slow = best): Slow</dl> |
| - | <dl class="li" style="margin-right:50px;"> Number of PSI-BLAST iterations in template search (PsiBLASTs): 3</dl> | + | <dl class="li" style="margin-right:50px;">- Number of PSI-BLAST iterations in template search (PsiBLASTs): 3</dl> |
| - | <dl class="li" style="margin-right:50px;"> Maximum allowed PSI-BLAST E-value to consider template (EValue Max): 0.5</dl> | + | <dl class="li" style="margin-right:50px;">- Maximum allowed PSI-BLAST E-value to consider template (EValue Max): 0.5</dl> |
| - | <dl class="li" style="margin-right:50px;">Maximum number of templates to be used (Templates Total): 20</dl> | + | <dl class="li" style="margin-right:50px;">- Maximum number of templates to be used (Templates Total): 20</dl> |
| - | <dl class="li" style="margin-right:50px;">Maximum number of templates with same sequence (Templates SameSeq): 1</dl> | + | <dl class="li" style="margin-right:50px;">- Maximum number of templates with same sequence (Templates SameSeq): 1</dl> |
| - | <dl class="li" style="margin-right:50px;">Maximum oligomerization state (OligoState): 4 (tetrameric)</dl> | + | <dl class="li" style="margin-right:50px;">- Maximum oligomerization state (OligoState): 4 (tetrameric)</dl> |
| - | <dl class="li" style="margin-right:50px;">Maximum number of alignment variations per template: (Alignments): 5</dl> | + | <dl class="li" style="margin-right:50px;">- Maximum number of alignment variations per template: (Alignments): 5</dl> |
| - | <dl class="li" style="margin-right:50px;">Maximum number of conformations tried per loop (LoopSamples): 50</dl> | + | <dl class="li" style="margin-right:50px;">- Maximum number of conformations tried per loop (LoopSamples): 50</dl> |
| - | <dl class="li" style="margin-right:50px;">Maximum number of residues added to the termini (TermExtension): 10</dl> | + | <dl class="li" style="margin-right:50px;">- Maximum number of residues added to the termini (TermExtension): 10</dl> |
</ul> | </ul> | ||
| Line 375: | Line 384: | ||
<br> | <br> | ||
<br> | <br> | ||
| - | + | ||
| - | + | ||
<p text-aligne:left style="margin-left:50px; margin-right:50px"> | <p text-aligne:left style="margin-left:50px; margin-right:50px"> | ||
<font size="5" color="#F0F8FF" face="Arial regular">First model LssmOrange</font> | <font size="5" color="#F0F8FF" face="Arial regular">First model LssmOrange</font> | ||
| - | </p> | + | </p><br> |
<font size="3" color="#F0F8FF" face="Arial regular"> | <font size="3" color="#F0F8FF" face="Arial regular"> | ||
| Line 410: | Line 418: | ||
<br> | <br> | ||
<br> | <br> | ||
| + | <div> | ||
<img alt="lssmOrange" src="/wiki/images/c/c1/LssmOrange_first_activeHelix.png" width="75%" height="75%" align="center"> | <img alt="lssmOrange" src="/wiki/images/c/c1/LssmOrange_first_activeHelix.png" width="75%" height="75%" align="center"> | ||
| - | + | </div> | |
<br> | <br> | ||
<font size="3" color="#F0F8FF" face="Arial regular"> | <font size="3" color="#F0F8FF" face="Arial regular"> | ||
<p text-aligne:center style="margin-left:50px; margin-right:50px"> | <p text-aligne:center style="margin-left:50px; margin-right:50px"> | ||
| - | <img alt="mod_qual" src="https://static.igem.org/mediawiki/2013/3/34/Lsso_3ned-a_quality.png" width="800" height="116" > | + | <div><img alt="mod_qual" src="https://static.igem.org/mediawiki/2013/3/34/Lsso_3ned-a_quality.png" width="800" height="116" align="center" > |
| - | + | </div> | |
<br> | <br> | ||
<br> | <br> | ||
| - | + | <font size="3" color="#F0F8FF" face="Arial regular"> | |
| + | <p text-aligne:center style="margin-left:50px; margin-right:50px"> | ||
Here, the first hybrid homology model of our protein, | Here, the first hybrid homology model of our protein, | ||
LssmOrange | LssmOrange | ||
is shown in ribbon representation. Furthermore, we illustrate the average quality z-score as a function of residue number. Nevertheless, it was subjected to a final round of simulated annealing minimization in explicit solvent and obtained the following quality Z-scores: | is shown in ribbon representation. Furthermore, we illustrate the average quality z-score as a function of residue number. Nevertheless, it was subjected to a final round of simulated annealing minimization in explicit solvent and obtained the following quality Z-scores: | ||
| - | + | </p></font> | |
<!-- Tabelle --> | <!-- Tabelle --> | ||
| Line 436: | Line 446: | ||
| - | <table border="1" style="background-color: transparent;"> | + | <table border="1" style="background-color: transparent; color:#F0F8FF; font-family:'Arial regular'"> |
<tr> | <tr> | ||
<th><b>Check Type</b></th> | <th><b>Check Type</b></th> | ||
| Line 472: | Line 482: | ||
| - | |||
| - | |||
| - | |||
<br> | <br> | ||
<br> | <br> | ||
| Line 481: | Line 488: | ||
<p text-aligne:left style="margin-left:50px; margin-right:50px"> | <p text-aligne:left style="margin-left:50px; margin-right:50px"> | ||
<font size="5" color="#F0F8FF" face="Arial regular">LssmOrange - second modelling</font> | <font size="5" color="#F0F8FF" face="Arial regular">LssmOrange - second modelling</font> | ||
| - | </p> | + | </p><br> |
<font size="3" color="#F0F8FF" face="Arial regular"> | <font size="3" color="#F0F8FF" face="Arial regular"> | ||
<p text-aligne:center style="margin-left:50px; margin-right:50px"> | <p text-aligne:center style="margin-left:50px; margin-right:50px"> | ||
| - | + | ||
This model is a monomer, and based on the following sequence alignment: | This model is a monomer, and based on the following sequence alignment: | ||
| - | < | + | <p text-aligne:left style="margin-left:60px; margin-right:60px"><font size="3" color="#F0F8FF" face="Arial regular"> |
| - | < | + | <div align="left" style="margin-left:30px; margin-right:50px"> |
| - | + | <ol> | |
| + | <li class=list1><b>SecStr:</b></li> | ||
| + | <li class=list1 style="max-width:1000px; word-wrap:break-word;"> CCCCCCCCCCCCCCCCEEEEEEEEEEECCEEEEEEEEEEECCCCCEEEEEEEEEECCCCCCCCCHHHCCCCCCCCCCCCCCCCCHHHHHHCCCCCEEEEEEEEEECCCEEEEEEEEEEECCEEEEEEEEEEECCCCCCCCCCCCCCCCCCEEEEEEEECCEEEEEEEEEEEECCCCEEEEEEEEEEECCCCCCCCCCEEEEEEEEEEEECCCCCEEEEEEEEEEECCCCCCCCCCC</li> | ||
| + | <li class=list1><b>Target:</b></li> | ||
| + | <li class=list1 style="max-width:1000px; word-wrap:break-word;"> MVSKGEENNMAIIKEFMRFKVRMEGSVNGHEFEIEGEGEGRPYEGFQTVKLKVTKGGPLPFAWDILSPQFTYGSKAYVKHPADIPDYLKLSFPEGFKWERVMNFEDGGVVTVTQDSSLQDGEFIYKVKLRGTNFPSDGPVMQKKTMGMEASSERMYPEDGALKGEDKLRLKLKDGGHYTSEVKTTYKAKKPVQLPGAYIVDIKLDITSHNEDYTIVEQYERAEGRHSTGGMDELYK<br>Match: AIIKEFMRFKV:MEGSVNGH FEIEGEGEGRPYEG QT:KLKVTKGGPLPF:WDILSPQF S:AYVKHPADIPDY:KLSFPEGFKWERVM:FEDGGVVTVTQDSSLQDGEFIYKVKLRGTNFPSDGPVMQKKTMG EA SERMYPEDGALKGE K R:KLKDGGHY :EVKTTYKAKKPVQLPGAY V: KLDITSHNEDYTIVEQYERAEGRHS | ||
| + | <br><li class=list1><b>Template:</b></li> | ||
| + | <li class=list1 style="max-width:1000px; word-wrap:break-word;"> ..........AIIKEFMRFKVHMEGSVNGHVFEIEGEGEGRPYEGTQTAKLKVTKGGPLPFTWDILSPQF...SNAYVKHPADIPDYFKLSFPEGFKWERVMKFEDGGVVTVTQDSSLQDGEFIYKVKLRGTNFPSDGPVMQKKTMGWEALSERMYPEDGALKGEVKPRVKLKDGGHYDAEVKTTYKAKKPVQLPGAYNVNRKLDITSHNEDYTIVEQYERAEGRHS.........<br> | ||
| + | <br><li class=list1><b>SecStr:</b></li> | ||
| + | <li class=list1 style="max-width:1000px; word-wrap:break-word;"> ..........CCCCCCEEEEEEEEEEETTEEEEEEEEEEEETTTEEEEEEEEEEECCCCCCCCCCGGGGC...TTTTCECTTTTCHHHHHHCCCEEEEEEEEEETTEEEEEEEEEEEEETTEEEEEEEEEEECCTTTTCTTTTCCEEEECEEEEEEEETTEEEEEEEEEEEETTEEEEEEEEEEEEEECCCCCCCCCEEEEEEEEEEEEETTTEEEEEEEEEEEECC.........</list> | ||
| + | </ol> | ||
| + | </div> | ||
| + | </font></p> | ||
| + | <br> | ||
<font size="3" color="#F0F8FF" face="Arial regular"> | <font size="3" color="#F0F8FF" face="Arial regular"> | ||
| Line 501: | Line 520: | ||
<br> | <br> | ||
<br> | <br> | ||
| - | <img alt="lssmOrange" src="/wiki/images/9/9d/LssmOrange_second_activeHelix_surface.png" width="75%" height="75%" align="center"> | + | <div align="center"> |
| + | <img alt="lssmOrange" src="/wiki/images/9/9d/LssmOrange_second_activeHelix_surface.png" width="75%" height="75%" align="center"></div> | ||
<br> | <br> | ||
| Line 507: | Line 527: | ||
<font size="3" color="#F0F8FF" face="Arial regular"> | <font size="3" color="#F0F8FF" face="Arial regular"> | ||
| - | <p text-aligne:center style="margin-left:50px; margin-right:50px"> | + | <p text-aligne:center style="margin-left:50px; margin-right:50px"><div align="Center"> |
| - | <img alt="mod_qual" src="https://static.igem.org/mediawiki/2013/9/90/Lsso_3kcs-a_quality.png" width="800" height="116" > | + | <img alt="mod_qual" src="https://static.igem.org/mediawiki/2013/9/90/Lsso_3kcs-a_quality.png" width="800" height="116" ></div> |
<br> | <br> | ||
| - | <br> | + | <br><font size="3" color="#F0F8FF" face="Arial regular"> |
| + | <p text-aligne:center style="margin-left:50px; margin-right:50px"> | ||
Here, the second hybrid homology model of our protein, | Here, the second hybrid homology model of our protein, | ||
LssmOrange | LssmOrange | ||
| - | is shown in ribbon representation. Again, we illustrate the average quality z-score as a function of residue number and obtained the following quality Z-scores: | + | is shown in ribbon representation. Again, we illustrate the average quality z-score as a function of residue number and obtained the following quality Z-scores: </p></font> |
| + | |||
| - | |||
<br> | <br> | ||
<br> | <br> | ||
| - | <table border="1"> | + | <table border="1" style="background-color: transparent; color:#F0F8FF; font-family:'Arial regular'"> |
<tr> | <tr> | ||
<th><b>Check Type</b></th> | <th><b>Check Type</b></th> | ||
| Line 559: | Line 580: | ||
<br> | <br> | ||
| - | |||
| - | |||
<br> | <br> | ||
| Line 568: | Line 587: | ||
<font size="5" color="#F0F8FF" face="Arial regular">Third model LssmOrange (dimer)</font> | <font size="5" color="#F0F8FF" face="Arial regular">Third model LssmOrange (dimer)</font> | ||
</p> | </p> | ||
| - | + | <br> | |
<font size="3" color="#F0F8FF" face="Arial regular"> | <font size="3" color="#F0F8FF" face="Arial regular"> | ||
<p text-aligne:center style="margin-left:50px; margin-right:50px"> | <p text-aligne:center style="margin-left:50px; margin-right:50px"> | ||
| - | + | ||
This model is a dimer, add based on the following sequence alignment: | This model is a dimer, add based on the following sequence alignment: | ||
| - | < | + | <p text-aligne:left style="margin-left:60px; margin-right:60px"><font size="3" color="#F0F8FF" face="Arial regular"> |
| - | < | + | <div align="left" style="margin-left:30px; margin-right:50px"> |
| - | + | <ol> | |
| + | <li class=list1><b>SecStr:</b></li> | ||
| + | <li class=list1 style="max-width:1000px; word-wrap:break-word;"> CCCCCCCCCCCCCCCCEEEEEEEEEEECCEEEEEEEEEEECCCCCEEEEEEEEEECCCCCCCCCHHHCCCCCCCCCCCCCCCCCHHHHHHCCCCCEEEEEEEEEECCCEEEEEEEEEEECCEEEEEEEEEEECCCCCCCCCCCCCCCCCCEEEEEEEECCEEEEEEEEEEEECCCCEEEEEEEEEEECCCCCCCCCCEEEEEEEEEEEECCCCCEEEEEEEEEEECCCCCCCCCCC<br>Target: MVSKGEENNMAIIKEFMRFKVRMEGSVNGHEFEIEGEGEGRPYEGFQTVKLKVTKGGPLPFAWDILSPQFTYGSKAYVKHPADIPDYLKLSFPEGFKWERVMNFEDGGVVTVTQDSSLQDGEFIYKVKLRGTNFPSDGPVMQKKTMGMEASSERMYPEDGALKGEDKLRLKLKDGGHYTSEVKTTYKAKKPVQLPGAYIVDIKLDITSHNEDYTIVEQYERAEGRHSTGGMDELYK<br>Match: |IKE M::K: MEG:VN:H:F: :EGEG|PYEG QT ||KV::GGPLPFA:DIL: SK:||:H IPD| K SFPEGF WERV :|EDGGV:T:TQD:SLQDG :IY:VK|RG:NFPS:GPVMQKKT|G EA::E MYP DG:L:G:: | LKL GGH ::KTTY|:KKP |PG:Y VD |L| :: | T VEQ|E A :R| <br>Template:...........LIKENMHMKLYMEGTVNNHHFKCTSEGEGKPYEGTQTQRIKVVEGGPLPFAFDILA......SKTFINHTQGIPDFWKQSFPEGFTWERVTTYEDGGVLTATQDTSLQDGCLIYNVKIRGVNFPSNGPVMQKKTLGWEANTEMMYPADGGLEGRNYMALKLVGGGHLICSLKTTYRSKKP..MPGVYYVDRRLERIKEADKETYVEQHEVAVARY.......... | ||
| + | SecStr: ...........CCCCCEEEEEEEEEEETTEEEEEEEEEEEETTTEEEEEEEEEEECCCCCCGGGGGG......TTTTCEEETTTCCCTTTTCCCEEEEEEEEEETTEEEEEEEEEEEEETTEEEEEEEEEEECCTTTTCTTTTCCEEEECEEEEEEEETTEEEEEEEEEEEETTEEEEEEEEEEEEEECCG..CCCCEEEEEEEEEEEEETTTEEEEEEEEEEEEC.......... | ||
| + | </list> | ||
| + | </ol> | ||
| + | </div> | ||
| + | </font></p> | ||
| + | <br> | ||
| + | |||
<font size="3" color="#F0F8FF" face="Arial regular"> | <font size="3" color="#F0F8FF" face="Arial regular"> | ||
<p text-aligne:center style="margin-left:50px; margin-right:50px"> | <p text-aligne:center style="margin-left:50px; margin-right:50px"> | ||
In the alignment, 207 of 236 target residues (87.7%) are aligned to template residues. Among these aligned residues, the sequence identity is 58.0% and the sequence similarity is 73.9% ('similar' means that the BLOSUM62 score is > 0) | In the alignment, 207 of 236 target residues (87.7%) are aligned to template residues. Among these aligned residues, the sequence identity is 58.0% and the sequence similarity is 73.9% ('similar' means that the BLOSUM62 score is > 0) | ||
| - | <br> | + | <br><div align="center"> |
| - | <img align="center" alt="lssmOrange" src="/wiki/images/e/ed/LssmOrange_third_activeHelix_surface_light2.png" width="75%" height="75%" > | + | <img align="center" alt="lssmOrange" src="/wiki/images/e/ed/LssmOrange_third_activeHelix_surface_light2.png" width="75%" height="75%" ></div> |
<br> | <br> | ||
| Line 588: | Line 616: | ||
<font size="3" color="#F0F8FF" face="Arial regular"> | <font size="3" color="#F0F8FF" face="Arial regular"> | ||
| - | <p text-aligne:center style="margin-left:50px; margin-right:50px"> | + | <p text-aligne:center style="margin-left:50px; margin-right:50px"> <div align="center"> |
| - | <img alt="mod_qual" src="https://static.igem.org/mediawiki/2013/e/ef/Lsso_4kge-~02_quality.png" width="800" height="116" > | + | <img alt="mod_qual" src="https://static.igem.org/mediawiki/2013/e/ef/Lsso_4kge-~02_quality.png" width="800" height="116" ></div> |
<br> | <br> | ||
| - | <br> | + | <br><font size="3" color="#F0F8FF" face="Arial regular"> |
| + | <p text-aligne:center style="margin-left:50px; margin-right:50px"> | ||
Here, the third hybrid homology model of our protein, | Here, the third hybrid homology model of our protein, | ||
LssmOrange | LssmOrange | ||
is shown in ribbon representation. Again, we illustrate the average quality z-score as a function of residue number and obtained the following quality Z-scores: | is shown in ribbon representation. Again, we illustrate the average quality z-score as a function of residue number and obtained the following quality Z-scores: | ||
| - | + | </p></font> | |
<!-- Tabelle --> | <!-- Tabelle --> | ||
| Line 603: | Line 632: | ||
| - | <table border="1"> | + | <table border="1" style="background-color: transparent; color:#F0F8FF; font-family:'Arial regular'"> |
<tr> | <tr> | ||
<th><b>Check Type</b></th> | <th><b>Check Type</b></th> | ||
| Line 658: | Line 687: | ||
<font size="3" color="#F0F8FF" face="Arial regular"> | <font size="3" color="#F0F8FF" face="Arial regular"> | ||
<p text-aligne:left style="margin-left:50px; margin-right:50px"> | <p text-aligne:left style="margin-left:50px; margin-right:50px"> | ||
| - | + | <ol> | |
| - | + | <li> | |
| - | < | + | E. Krieger, G. Koraimann, and G. Vriend, “Increasing the precision of comparative models with YASARA NOVA--a self-parameterizing force field.,” Proteins, vol. 47, no. 3, pp. 393–402, 2002. |
| - | + | </li> | |
| - | + | <li> | |
| - | < | + | S. F. Altschul, T. L. Madden, A. A. Schäffer, J. Zhang, Z. Zhang, W. Miller, and D. J. Lipman, “Gapped BLAST and PSI-BLAST: a new generation of protein database search programs.,” Nucleic Acids Res, vol. 25, no. 17, pp. 3389–3402, Sep. 1997. |
| - | + | </li> | |
| - | + | <li> | |
| - | < | + | R. W. Hooft, G. Vriend, C. Sander, and E. E. Abola, “Errors in protein structures.,” Nature, vol. 381, no. 6580. Nature Publishing Group, p. 272, 1996. |
| - | + | </li> | |
| - | + | <li> | |
| - | < | + | D. T. Jones, “Protein secondary structure prediction based on position-specific scoring matrices,” Journal of Molecular Biology, vol. 292, no. 2, pp. 195–202, 1999. |
| - | + | </li> | |
| - | + | <li> | |
| - | < | + | A. A. Canutescu, A. A. Shelenkov, and R. L. Dunbrack, “A graph-theory algorithm for rapid protein side-chain prediction.,” Protein Science, vol. 12, no. 9, pp. 2001–2014, 2003. |
| - | + | </li> | |
| - | + | <li> | |
| - | < | + | E. Krieger, K. Joo, J. Lee, J. Lee, S. Raman, J. Thompson, M. Tyka, D. Baker, and K. Karplus, “Improving physical realism, stereochemistry, and side-chain accuracy in homology modeling: Four approaches that performed well in CASP8.,” Proteins, vol. 77 Suppl 9, no. June, pp. 114–122, 2009. |
| - | + | </li> | |
| - | + | <li> | |
| - | < | + | http://www.yasara.org/homologymodeling.htm |
| - | + | </li> | |
| + | </ol> | ||
</center> | </center> | ||
</body> | </body> | ||
</html> | </html> | ||
Latest revision as of 02:34, 5 October 2013
Homology Modelling
While our proteins are functionally described in literature and during the IGEM competition, only part of the structures are available in the protein data bank. For further work and visualizations, protein structures are indispensable. We used Yasara Structure [1] to calculate 3-dimensional structures of all of our proteins for the IGEM.
Workflow
Description how our Yasara script calculates homology model[7]:

- Sequence is PSI-BLASTed against Uniprot [2]
- Calculation of a position-specific scoring matrix (PSSM) from related sequences
- Using the PSSM to search the PDB for potential modeling templates
- The Templates are ranked based on the alignment score and the structural quality[3]
- Deriving additional information’s for template and target (prediction of secondary structure, structure-based alignment correction by using SSALN scoring matrices [4]).
- A graph of the side-chain rotamer network is built, dead-end elimination is used to find an initial rotamer solution in the context of a simple repulsive energy function [5]
- The loop-network is optimized using a high amount of different orientations
- Side-chain rotamers are fine-tuned considering electrostatic and knowledge-based packing interactions as well as solvation effects.
- An unrestrained high-resolution refinement with explicit solvent molecules is run, using the latest knowledge-based force fields[6].
Application
All these steps are performed to every template used for the modeling approach. For our project we set the maximum amount of templates to 20. Every derived structure is evaluated using an average per-residue quality Z-scores. At last a hybrid model is built containing the best regions of all predictions. This procedure make prediction’s accurate and thus more realistic. For the evaluation we used the Yasara Z-scores.A Z-score describes how many standard deviations the model quality is away from the average high-resolution X-ray structure. Negative values indicate that the homology model looks worse than a high-resolution X-ray structure. The overall Z-scores for all models have been calculated as the weighted averages of the individual Z-scores using the formula Overall = 0.145*Dihedrals + 0.390*Packing1D + 0.465*Packing3D [7].
Parameters
We used the Yasara script hm_build.mcr for the model creation with the following parameters:
- - Modeling speed (slow = best): Slow
- - Number of PSI-BLAST iterations in template search (PsiBLASTs): 3
- - Maximum allowed PSI-BLAST E-value to consider template (EValue Max): 0.5
- - Maximum number of templates to be used (Templates Total): 20
- - Maximum number of templates with same sequence (Templates SameSeq): 1
- - Maximum oligomerization state (OligoState): 4 (tetrameric)
- - Maximum number of alignment variations per template: (Alignments): 5
- - Maximum number of conformations tried per loop (LoopSamples): 50
- - Maximum number of residues added to the termini (TermExtension): 10
Results
Since the target sequence was the only available information, possible templates were identified by running 6 PSI-BLAST iterations to extract a position specific scoring matrix (PSSM) from Uniprot, and then searching the PDB for a match (i.e. hits with an E-value below the homology modeling cutoff 0.5)
We present the best three models from a total of 14 listed in the model ranking and sorted by their overall quality Z-scores.
First model LssmOrange
This model is a monomer, and based on the following sequence alignment:
In the alignment, 228 of 236 target residues (96.6%) are aligned to template residues. Among these aligned residues, the sequence identity is 93.0% and the sequence similarity is 94.7% ('similar' means that the BLOSUM62 score is > 0).
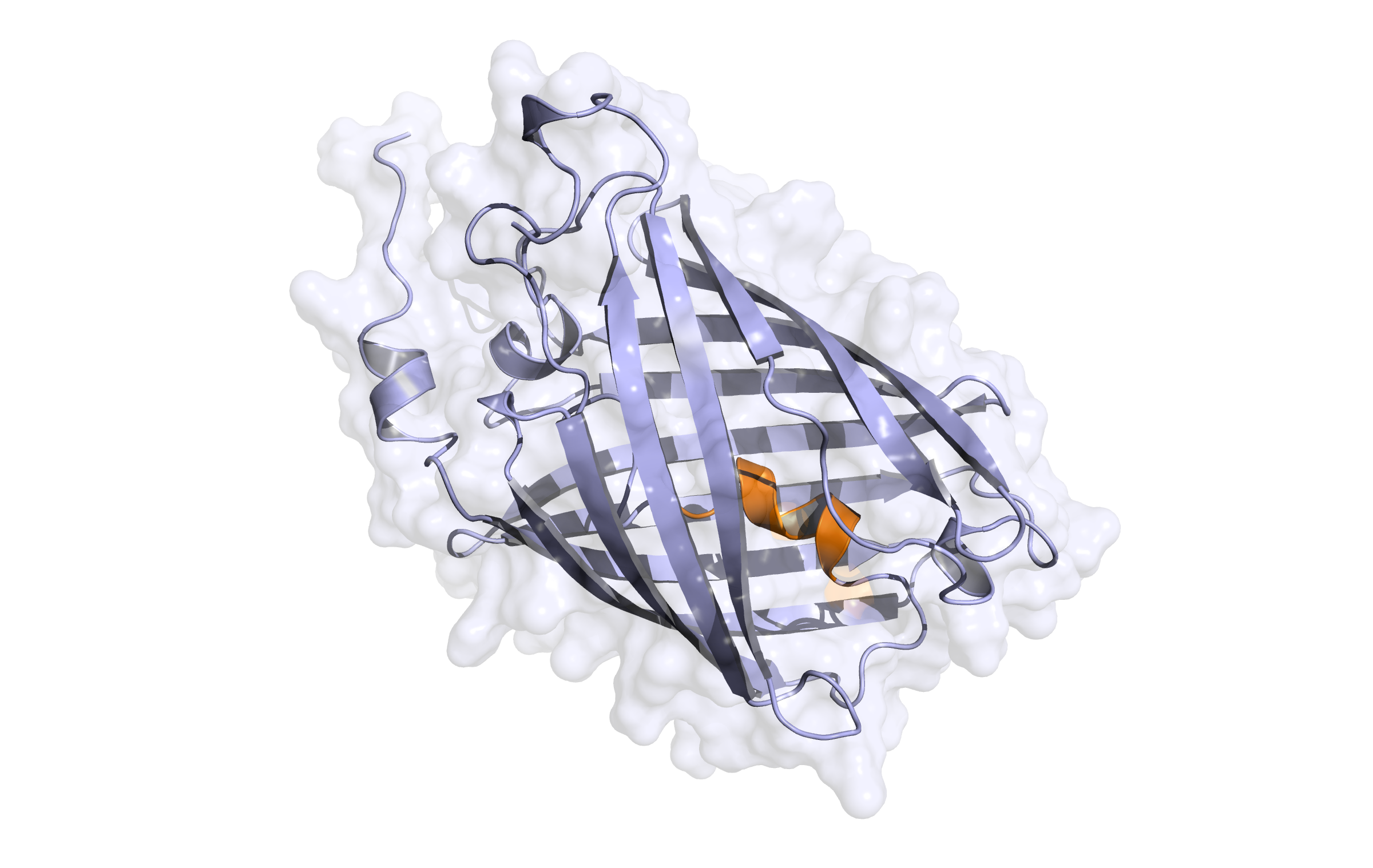

Here, the first hybrid homology model of our protein, LssmOrange is shown in ribbon representation. Furthermore, we illustrate the average quality z-score as a function of residue number. Nevertheless, it was subjected to a final round of simulated annealing minimization in explicit solvent and obtained the following quality Z-scores:
| Check Type | Quality Z-score | Comment |
|---|---|---|
| Dihedrals | 2.363 | Optimal |
| Packing 1D | -0.864 | Good |
| Packing 3D | -1.138 | Satisfactory |
| Overall | -0.524 | Good |
LssmOrange - second modelling
This model is a monomer, and based on the following sequence alignment:
Match: AIIKEFMRFKV:MEGSVNGH FEIEGEGEGRPYEG QT:KLKVTKGGPLPF:WDILSPQF S:AYVKHPADIPDY:KLSFPEGFKWERVM:FEDGGVVTVTQDSSLQDGEFIYKVKLRGTNFPSDGPVMQKKTMG EA SERMYPEDGALKGE K R:KLKDGGHY :EVKTTYKAKKPVQLPGAY V: KLDITSHNEDYTIVEQYERAEGRHS
In the alignment, 214 of 236 target residues (90.7%) are aligned to template residues. Among these aligned residues, the sequence identity is 91.6% and the sequence similarity is 93.0% ('similar' means that the BLOSUM62 score is > 0).
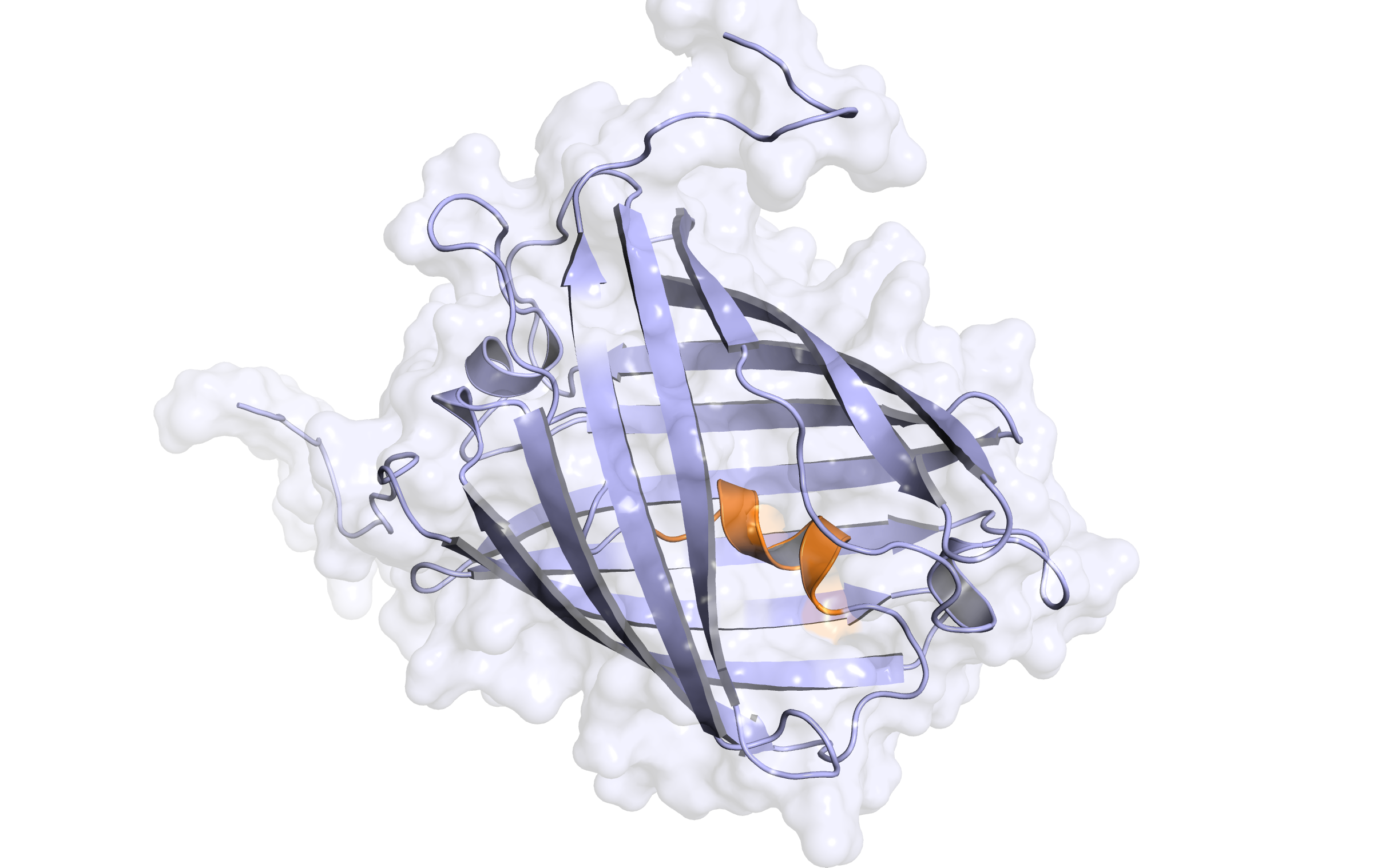

Here, the second hybrid homology model of our protein, LssmOrange is shown in ribbon representation. Again, we illustrate the average quality z-score as a function of residue number and obtained the following quality Z-scores:
| Check Type | Quality Z-score | Comment |
|---|---|---|
| Dihedrals | 2.125 | Optimal |
| Packing 1D | -0.936 | Good |
| Packing 3D | -1.259 | Satisfactory |
| Overall | -0.642 | Good |
Third model LssmOrange (dimer)
This model is a dimer, add based on the following sequence alignment:
Target: MVSKGEENNMAIIKEFMRFKVRMEGSVNGHEFEIEGEGEGRPYEGFQTVKLKVTKGGPLPFAWDILSPQFTYGSKAYVKHPADIPDYLKLSFPEGFKWERVMNFEDGGVVTVTQDSSLQDGEFIYKVKLRGTNFPSDGPVMQKKTMGMEASSERMYPEDGALKGEDKLRLKLKDGGHYTSEVKTTYKAKKPVQLPGAYIVDIKLDITSHNEDYTIVEQYERAEGRHSTGGMDELYK
Match: |IKE M::K: MEG:VN:H:F: :EGEG|PYEG QT ||KV::GGPLPFA:DIL: SK:||:H IPD| K SFPEGF WERV :|EDGGV:T:TQD:SLQDG :IY:VK|RG:NFPS:GPVMQKKT|G EA::E MYP DG:L:G:: | LKL GGH ::KTTY|:KKP |PG:Y VD |L| :: | T VEQ|E A :R|
Template:...........LIKENMHMKLYMEGTVNNHHFKCTSEGEGKPYEGTQTQRIKVVEGGPLPFAFDILA......SKTFINHTQGIPDFWKQSFPEGFTWERVTTYEDGGVLTATQDTSLQDGCLIYNVKIRGVNFPSNGPVMQKKTLGWEANTEMMYPADGGLEGRNYMALKLVGGGHLICSLKTTYRSKKP..MPGVYYVDRRLERIKEADKETYVEQHEVAVARY..........
SecStr: ...........CCCCCEEEEEEEEEEETTEEEEEEEEEEEETTTEEEEEEEEEEECCCCCCGGGGGG......TTTTCEEETTTCCCTTTTCCCEEEEEEEEEETTEEEEEEEEEEEEETTEEEEEEEEEEECCTTTTCTTTTCCEEEECEEEEEEEETTEEEEEEEEEEEETTEEEEEEEEEEEEEECCG..CCCCEEEEEEEEEEEEETTTEEEEEEEEEEEEC..........
In the alignment, 207 of 236 target residues (87.7%) are aligned to template residues. Among these aligned residues, the sequence identity is 58.0% and the sequence similarity is 73.9% ('similar' means that the BLOSUM62 score is > 0)
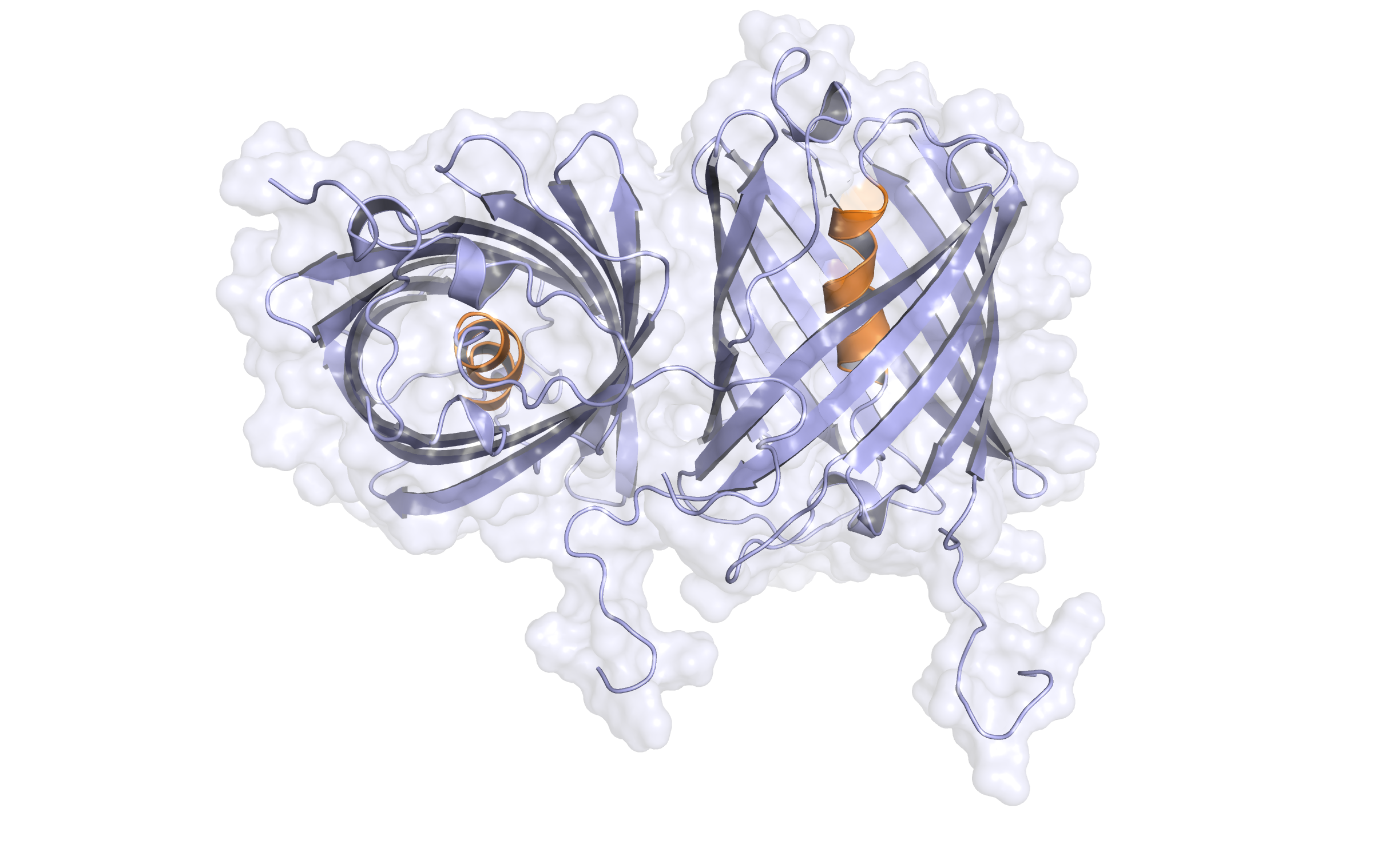

Here, the third hybrid homology model of our protein, LssmOrange is shown in ribbon representation. Again, we illustrate the average quality z-score as a function of residue number and obtained the following quality Z-scores:
| Check Type | Quality Z-score | Comment |
|---|---|---|
| Dihedrals | 1.237 | Optimal |
| Packing 1D | -2.083 | Poor |
| Packing 3D | -1.651 | Satisfactory |
| Overall | -1.400 | Satisfactory |
References
- E. Krieger, G. Koraimann, and G. Vriend, “Increasing the precision of comparative models with YASARA NOVA--a self-parameterizing force field.,” Proteins, vol. 47, no. 3, pp. 393–402, 2002.
- S. F. Altschul, T. L. Madden, A. A. Schäffer, J. Zhang, Z. Zhang, W. Miller, and D. J. Lipman, “Gapped BLAST and PSI-BLAST: a new generation of protein database search programs.,” Nucleic Acids Res, vol. 25, no. 17, pp. 3389–3402, Sep. 1997.
- R. W. Hooft, G. Vriend, C. Sander, and E. E. Abola, “Errors in protein structures.,” Nature, vol. 381, no. 6580. Nature Publishing Group, p. 272, 1996.
- D. T. Jones, “Protein secondary structure prediction based on position-specific scoring matrices,” Journal of Molecular Biology, vol. 292, no. 2, pp. 195–202, 1999.
- A. A. Canutescu, A. A. Shelenkov, and R. L. Dunbrack, “A graph-theory algorithm for rapid protein side-chain prediction.,” Protein Science, vol. 12, no. 9, pp. 2001–2014, 2003.
- E. Krieger, K. Joo, J. Lee, J. Lee, S. Raman, J. Thompson, M. Tyka, D. Baker, and K. Karplus, “Improving physical realism, stereochemistry, and side-chain accuracy in homology modeling: Four approaches that performed well in CASP8.,” Proteins, vol. 77 Suppl 9, no. June, pp. 114–122, 2009.
- http://www.yasara.org/homologymodeling.htm