 "
"
Team:Alberta/Results
From 2013.igem.org
| Line 586: | Line 586: | ||
<h2>Problems with Expansion</h2> | <h2>Problems with Expansion</h2> | ||
<p>Our existing system functions well as a proof-of-concept, but won’t be able to expand far beyond the scope of a four-city problem, which limits its usefulness. Adding just a fifth city to the problem also adds four new paths, and thus four new genes, which will in turn require a more complex filtration and identification method. Adding a sixth city increases the required number of new genes to nine, and a seventh makes it 15 – at this rate, we will rapidly run out of possible selection markers and reporter genes. </p> | <p>Our existing system functions well as a proof-of-concept, but won’t be able to expand far beyond the scope of a four-city problem, which limits its usefulness. Adding just a fifth city to the problem also adds four new paths, and thus four new genes, which will in turn require a more complex filtration and identification method. Adding a sixth city increases the required number of new genes to nine, and a seventh makes it 15 – at this rate, we will rapidly run out of possible selection markers and reporter genes. </p> | ||
| - | <img src=" | + | <img src="/wiki/images/1/12/2013-Alberta-expansion-problems.png" style="width:100%;"></img> |
<p>What we need is a method that handles the parts of the problem, paths and cities, in a different way, allowing us to expand without the need for as many unique genes. </p> | <p>What we need is a method that handles the parts of the problem, paths and cities, in a different way, allowing us to expand without the need for as many unique genes. </p> | ||
</div> | </div> | ||
Revision as of 23:41, 27 September 2013
The Littlest Mapmaker
"Exploration into the world of DNA Computing"
Team Alberta: University of Alberta

Results
The Setup
Our project’s modified parts were produced via PCR from existing stocks of BioBricks, then cloned into pSB1C3 plasmids for mass production. The parts were separated from the plasmid by restriction digestion with BsaI enzyme, and then the desired strands were purified by HPLC to ensure there could be no contamination by other DNA strands capable of interacting with our custom sticky ends.
The First Tests
We performed some initial tests to confirm the efficacy of our assembly system. In the gel below, the second lane displays the result of an origin of replication (Ori) sample that was bound to the bead, washed and then re-eluted – the presence of DNA at the desired mass in this lane confirms the successful binding and elution. The third lane demonstrates that we can successfully ligate genes (KanR in this case) directly to the Ori at high efficiency and still safely elute them. In the fourth lane, we have ligated a 13-base-pair linker onto the existing Ori-KanR, followed by a second gene, ChlorR. Although the high-mass band suggests that ligation was successful, the fact that there is still a stronger band at the Ori-KanR mass suggests that the ligation has not proceeded to completion.
IMAGE
Figure 1: Agarose gel electrophoresis image from initial ligation trials.
Lane 1: DNA Markers
Lane 2: Origin of replication, bound to the magnetic beads and then eluted.
Lane 3: KanR gene ligated to bead-bound Ori.
Lane 4: Existing bead-bound Ori-KanR sample ligated with linker, then ligated with ChlorR
(beads are always washed between ligations).
Perfecting the Linkers
To get a more effective ligation without extending the timeframe of our assembly, we made several adjustments. First, we raised ligation temperature from 4°C to 22°C in the hopes of increasing the enzyme activity. We switched to a larger, 25-base-pair linker – we were able to successfully ligate large pieces in the case of the Ori and KanR ligation, so perhaps size plays a factor. We used better-purified stocks of our genes, to eliminate the possibility that some interfering piece of the original plasmid was competing with our desired reaction. Finally, we attempted to increase the concentration of the linker in the hopes of driving the reaction to completion. Here, we can see that our changes have significantly improved the ligation efficiency, although changing the linker concentration has not created an appreciable benefit.
IMAGE
Figure 2: Agarose gel electrophoresis image from linker concentration comparison after
ligation protocol adjustments.
Lane 1: DNA Markers
Lane 2: Ori-KanR ligation to linker, then to ChlorR (as in Figure 1, Lane 4) using 10:1 ratio of
linker to Ori.
Lane 3: As lane 2, with 50:1 ratio.
Lane 4: As lane 3, with 100:1 ratio.
The Full Assembly
With our successful ligation protocol established, we moved on to attempting a full-scale assembly, with four genes (the quantity required for our proof-of-concept travelling salesman problem). In this gel, the four lanes show the successive addition of the four genes, which are, for the most part, successful. In each lane, there is some remainder of the previous products left behind, including (presumably) instances of strands that were incomplete in one reaction continuing to acquire genes in a successive one. Regardless, these incomplete genes represent only a small fraction of the total DNA.
IMAGE
Figure 3: Agarose gel electrophoresis image from full assembly test.
Lane 1: DNA Markers.
Lane 2: Ori to KanR ligation product.
Lane 3: Ori-KanR to linker to GFP ligation product.
Lane 4: Ori-KanR-Linker-GFP to linker to RFP ligation product.
Lane 5: Ori-KanR-Linker-GFP-Linker-RFP to linker to ChlorR ligation product.
The product plasmids from this assembly were transformed into a bacterial culture and grown on a Kan/Chlor plate to examine practical impact of the rate of incomplete ligations. The plate image is shown below – about 90% of the colonies display the desired RFP/GFP (orange colouration) phenotype indicating a perfect successful ligation of the plasmid.
Colour Controls
In our planned, four-city proof-of-concept test (see the map below), there are exactly three possible solutions and three corresponding phenotypes: blue/green (dark green) bacteria with Amp/Chlor resistance, red/green (orange) bacteria with Chlor/Kan resistance, and red/blue (purple) bacteria with Amp/Kan resistance.
To ensure we would be able to correctly identify plasmids based on phenotype we prepared a set of control plates, where bacteria grown from pure assemblies of the desired “route” plasmid were grown alongside bacteria possessing only one of the two colours from that route, for comparison purposes. The resulting plates can be seen below.
Initial Calibration
In preparation for our initial travelling salesman problems, we attempted to discern the extent to which unexpected or unknown biases might affect the frequency of colonies growing with a particular gene.
In this test, we performed an assembly in which both GFP and aCP were included (in equal molar concentration) in the initial ligation onto the Ori, followed by a ligation of ChlorR, resulting in a mixture of Ori-GFP-ChlorR and Ori-aCP-ChlorR plasmids. We transformed these plasmids into a single bacterial culture, which we then spread on a Chlor-treated plate in order to count the resulting colonies. We repeated this test for each of the other four genes to be used in our proof-of-concept TSP, comparing each against GFP as a standard. This provided us with the following ratios of growth.
Table 1:
1GFP 6aCP
We then attempted another assembly in which we calibrated for the bias. We used a 6:1 molar ratio of GFP to aCP in the new assembly, otherwise performing the experiment as before, and produced a new plate with a ratio of approximately 1:1 GFP colonies to aCP colonies. Although imperfect, this calibration was adequate for our proof-of-concept trial.
The Equidistant Salesman
Our first attempt at any TSP was merely to demonstrate that the system is capable of selecting different routes when given the full range of possibilities. The equidistant travelling salesman problem uses a map of cities in which every city is exactly the same distance away from every other city, such that there is no preference for one path over another, and thus all genes are added to the assembly so as to yield identical colony production (incorporating our initial calibration values). There is no optimal solution for this problem, as all routes are exactly the same length.
The assembly was otherwise as we would treat a real TSP, and the resulting plates can be seen below. The plates in this case have no clear preference for any path, but do display the variety of phenotypes that one can expect from an assembly of this sort, where there are as many as 27 different possible plasmids.
The Travelling Salesman Problem
We have conducted a single successful travelling salesman problem. This problem was based on a map of four cities in which four of the paths have an arbitrary unit distance of 1, and the remaining two paths have a distance of 4. Of the possible routes in this problem, one route has a total sum distance of 4, and the other two have distances of 10, making that route clearly preferable, and a suitable test of our biocomputer. The map, with correct gene-path assignment for this problem, can be seen below.
On the resulting plates, we counted only one colony corresponding to the ChlorR/GFP/aCP/AmpR route, and 10 colonies corresponding to the ChlorR/RFP/GFP/KanR route. For the optimal route, KanR/aCP/RFP/AmpR, we found 61 colonies, clearly identifying this as the solution to the problem.
While technically a success in terms of its ability to correctly solve this TSP, the trial also demonstrated flaws in our mathematics and scale. With colony counts numbering less than 100 for each solution, the system needs to have much better transformation efficiency, and needs much larger quantities of colonies in total if we hope to confirm a solution statistically. Additionally, the ratios that result from using a simple reciprocal of distance, as we do, are not as accurate as they might be. We have endeavoured to address all of these issues, and more, in the Future Developments page in the Project section.
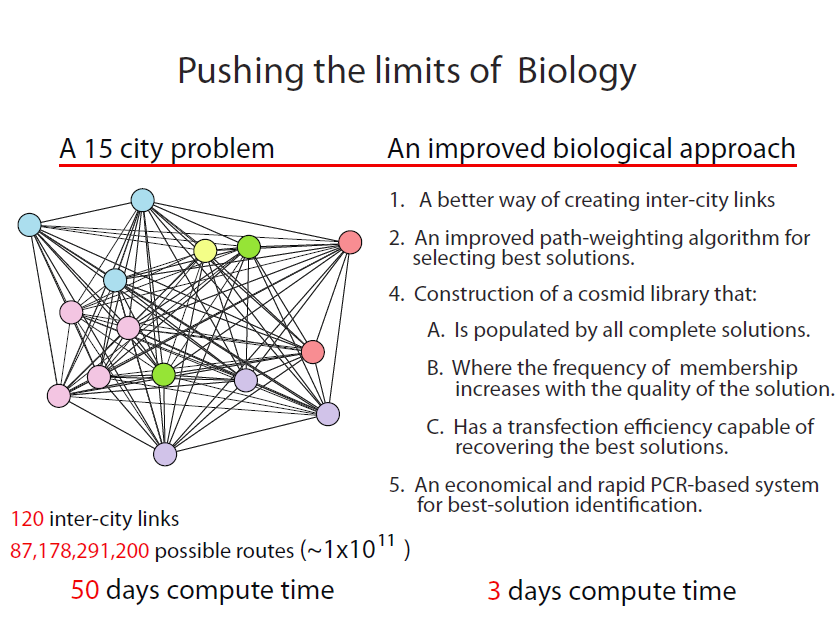

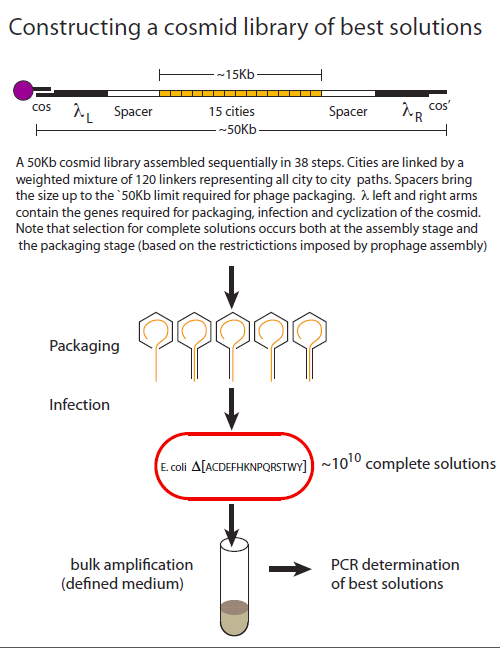

Project Future
Problems with Expansion
Our existing system functions well as a proof-of-concept, but won’t be able to expand far beyond the scope of a four-city problem, which limits its usefulness. Adding just a fifth city to the problem also adds four new paths, and thus four new genes, which will in turn require a more complex filtration and identification method. Adding a sixth city increases the required number of new genes to nine, and a seventh makes it 15 – at this rate, we will rapidly run out of possible selection markers and reporter genes.

What we need is a method that handles the parts of the problem, paths and cities, in a different way, allowing us to expand without the need for as many unique genes.
Redefining the Terms
Our planned solution to this problem uses genes to symbolize the cities, rather than the paths in between them. In this way, the addition of a new city only requires that we add one new gene, instead of several. It also requires, however, that we make some adjustments to our assembly system, in particular in terms of how we use the small 25-base-pair linkers. In this new system, the linkers connecting the genes will symbolize the paths, which means that we will need several unique linkers to represent all of the different paths in the problem. This is achieved by changing the sticky ends on the linkers and genes so that each linker is only able to ligate with two specific genes, thus it symbolizes a path connecting those two cities. This will in turn mean that the addition of each city will require us to engineer two new sticky ends, but since variation of those short sequences of base pairs is relatively easy to perform on a large scale, this effectively resolves the issue of being able to symbolize all of the paths.
Being left with the problem of how to create as many as 15 or 20 selectable markers, we would ideally use a bacterial strain that is auxotrophic for as many amino acids as are required for the problem. Grown in minimal media and using genes that allow for production of the knocked out amino acids as our cities, we could ensure that there is no incidence at all of invalid solutions: any plasmid that does not contain all of the genes on the map, and thus does not feature a valid route travelling to every city, will not be able to persist in the minimal growth medium. The new four-city map for this version of the problem can be seen below.