 "
"
Team:Tsinghua-A/md
From 2013.igem.org
| Line 201: | Line 201: | ||
<section id="exp" class="section blue"> | <section id="exp" class="section blue"> | ||
<div class="container"> | <div class="container"> | ||
| - | <h4> | + | <h4>Basic Function Analysis -- Massive Parallel Data Processing</h4> |
<div class="row"> | <div class="row"> | ||
| Line 207: | Line 207: | ||
<p > | <p > | ||
| - | + | The ideal network in our project must be sensitive to the input signal and be able to distinguish the low input and high input from each other. So we expected that the target structure should have a low-input-low-output and high-input-high-output character. Besides, it should avoid ambiguous interim region between low input and high input. | |
</br></br> | </br></br> | ||
| - | <img src="https://static.igem.org/mediawiki/2013/ | + | <img src="https://static.igem.org/mediawiki/2013/b/ba/Model4.jpg" alt="" style="margin:auto;display:block;text-align:center"/> |
| + | </br></br> | ||
| + | We firstly raised two basic indexes, High-low Ratio and Interim Slope to evaluate the performance of all three-node network structures. To each structure, we scanned the value of input ranging from 1 to 1000 and recorded the corresponding output. | ||
</br> | </br> | ||
| - | |||
</br> | </br> | ||
| + | <img src="https://static.igem.org/mediawiki/2013/d/d6/Model5.jpg" alt="" style="margin:auto;display:block;text-align:center"/> | ||
| + | </br> | ||
</br> | </br> | ||
| - | + | Then we enumerated all possible network structures and illustrated the filtering result in a 2D map. The X-axis represents High-low Ratio and the Y-axis represents Interim Slope, and there are 19683 three-node structures illustrated as docs in grids in the map. | |
| + | </br></br> | ||
| + | According to our target, only networks with high High-low Ratio and high Interim Slope can achieve the required function. In other words, only networks located in the top-right corner of the map are acceptable. | ||
</br></br> | </br></br> | ||
| - | <img src="https://static.igem.org/mediawiki/2013/ | + | <img src="https://static.igem.org/mediawiki/2013/2/24/Model6.jpg" alt="" style="margin:auto;display:block;text-align:center"/> |
</br> | </br> | ||
| - | + | <img src="https://static.igem.org/mediawiki/2013/4/44/Model7.jpg" alt="" style="margin:auto;display:block;text-align:center"/> | |
| + | </br></br> | ||
| + | Finally we screened 476 three-node network structures out of 19683 network structures in total, which can achieve the high High-low Ratio and high Interim Slope. </br></br> | ||
| + | The whole process involved massive calculation and parallel data processing. Especially, it requires serious computing power to solve all the ODE equations of 19683 networks and computer cluster is a powerful tool. Computer cluster connects a group of incompact computers which collaborate together to offer stronger processor power and larger space. We finished the first round of screening with the help of High Performance Computing Cluster (HPCC) in Tsinghua University. </br></br> | ||
| + | |||
</p> | </p> | ||
Revision as of 19:44, 27 September 2013
Overview
The expression of interacting genes depends on the structure of gene regulatory networks (GRN). In order to figure out optimal biological networks that can function reliably when faced with fluctuation of DNA template amount (copy number), it is important to do some simulations in advance to narrow the screening scope and theoretically discuss certain functional regulatory motifs that are significant in showing adaptation. Therefore, it would be easier for us to search for and verify adaptive and robust networks in wet lab. In our project, we abstractly analyzed gene regulatory network topologies and computed all possible three-node network structures by enumeration. We modeled, calculated, tested and made comparisons, and finally screened 2 core optimal network structures out of 19683 network structures, which show great adaptation to DNA copy number. In order to verify the correctness of our screening result, we introduced an optimal testing case and simulated. Based on our screening results, we analyzed and concluded 9 key motifs that may be essential to adaptation. We respectively simulated these motifs and tried to explain their characters with mathematical proof. Finally we figured out that these key motifs can be combined to obtain better effects.
Construction of Networks And Description Mathematical Description -- ODE Equations
We based on the Michealis-Menten Equation and Hill Equation to describe the kinetics of gene regulatory networks. The M-M Equation and Hill Equation describe the relationship between the production rate of products and the concentration of substrate.
M-M Equations of activation (monotone-increasing) and inhibition (monotone-decreasing) are defined as:
〖f(X)〗_activition=CX/(K+X)
〖f(X)〗_inhibition=CK/(K+X)
Hill Equations of activation (monotone-increasing) and inhibition (monotone-decreasing) are defined as:
〖f(X)〗_activition=(CX^n)/(K^n+X^n )
〖f(X)〗_inhibition=(CK^n)/(K^n+X^n )
(C is a constant, K is called half maximal effective concentration and n is called hill coefficient.)
In our project, we aimed at all three-node network structures, and each contains 4 nodes (1 input node, 2 regulatory nodes and 1 output node) and vast possible regulatory edges among them.
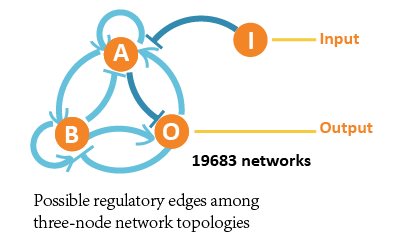
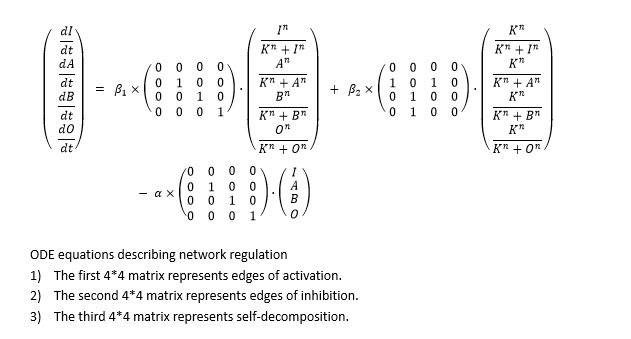
 So we formed ODE equation sets to describe the mutual relationships and form networks. The ODE equation sets involve two 4*4 matrices to respectively bring in the activating effect and inhibitive effect, and a column vector for self-decomposition.
So we formed ODE equation sets to describe the mutual relationships and form networks. The ODE equation sets involve two 4*4 matrices to respectively bring in the activating effect and inhibitive effect, and a column vector for self-decomposition.
 In our wet lab part, we synthetized network and constructed plasmids transferred into Hela cells, and we made some adjustment in our design for a better realization in experiment:
We assumed that input (I) is not regulated by the network and remained constant.
We fixed two certain edges (I inhibits A, A inhibits O), because when constructing the system, the components to function as inducers are quite few. So we tend to use 2 repressors to substitute it.
We limited the maximum number of regulatory nodes to 2 restrict the problem to an acceptable scale.
We chose relative parameters close to the actual experiments in our simulation. According to previous research, we guaranteed that most parameters are within the already confirmed range, such as reaction rate.
In our wet lab part, we synthetized network and constructed plasmids transferred into Hela cells, and we made some adjustment in our design for a better realization in experiment:
We assumed that input (I) is not regulated by the network and remained constant.
We fixed two certain edges (I inhibits A, A inhibits O), because when constructing the system, the components to function as inducers are quite few. So we tend to use 2 repressors to substitute it.
We limited the maximum number of regulatory nodes to 2 restrict the problem to an acceptable scale.
We chose relative parameters close to the actual experiments in our simulation. According to previous research, we guaranteed that most parameters are within the already confirmed range, such as reaction rate.
Basic Function Analysis -- Massive Parallel Data Processing
The ideal network in our project must be sensitive to the input signal and be able to distinguish the low input and high input from each other. So we expected that the target structure should have a low-input-low-output and high-input-high-output character. Besides, it should avoid ambiguous interim region between low input and high input.
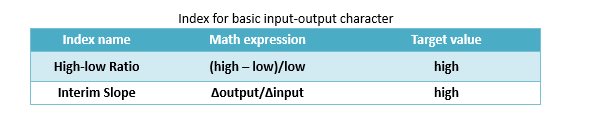
 We firstly raised two basic indexes, High-low Ratio and Interim Slope to evaluate the performance of all three-node network structures. To each structure, we scanned the value of input ranging from 1 to 1000 and recorded the corresponding output.
We firstly raised two basic indexes, High-low Ratio and Interim Slope to evaluate the performance of all three-node network structures. To each structure, we scanned the value of input ranging from 1 to 1000 and recorded the corresponding output.
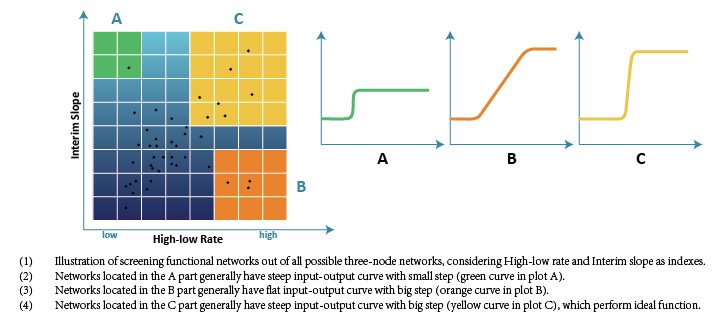
 Then we enumerated all possible network structures and illustrated the filtering result in a 2D map. The X-axis represents High-low Ratio and the Y-axis represents Interim Slope, and there are 19683 three-node structures illustrated as docs in grids in the map.
According to our target, only networks with high High-low Ratio and high Interim Slope can achieve the required function. In other words, only networks located in the top-right corner of the map are acceptable.
Then we enumerated all possible network structures and illustrated the filtering result in a 2D map. The X-axis represents High-low Ratio and the Y-axis represents Interim Slope, and there are 19683 three-node structures illustrated as docs in grids in the map.
According to our target, only networks with high High-low Ratio and high Interim Slope can achieve the required function. In other words, only networks located in the top-right corner of the map are acceptable.
 Finally we screened 476 three-node network structures out of 19683 network structures in total, which can achieve the high High-low Ratio and high Interim Slope.
The whole process involved massive calculation and parallel data processing. Especially, it requires serious computing power to solve all the ODE equations of 19683 networks and computer cluster is a powerful tool. Computer cluster connects a group of incompact computers which collaborate together to offer stronger processor power and larger space. We finished the first round of screening with the help of High Performance Computing Cluster (HPCC) in Tsinghua University.
Finally we screened 476 three-node network structures out of 19683 network structures in total, which can achieve the high High-low Ratio and high Interim Slope.
The whole process involved massive calculation and parallel data processing. Especially, it requires serious computing power to solve all the ODE equations of 19683 networks and computer cluster is a powerful tool. Computer cluster connects a group of incompact computers which collaborate together to offer stronger processor power and larger space. We finished the first round of screening with the help of High Performance Computing Cluster (HPCC) in Tsinghua University.
Parts
| Name | description | Part Type | Designer |
| K1116000 | LacI with miR-21 and miR-FF3 target | Composite | Lei Wei |
| K1116001 | LacI with miR-21 and miR-FF5 target | Composite | Shuguang Peng |
| K1116002 | TRE-LacI with miR-21 and miR-FF3 target | Composite | Shuguang Peng |
| K1116003 | TRE-LacI with miR-21 and miR-FF5 target | Composite | Shuguang Peng |
| K1116004 | CAG-EYFP-miRNA-FF3 | Composite | Shuguang Peng |
| K1116005 | CAG-Cerulean-hsa-miR-21 | Composite | Shuguang Peng |
Discussion
Due to some restrictions in wetlab, we only finished the above-mentioned experiment. We found that the number of Hela cells who possesses high copy number is comparatively low. We also noticed the circuit C’s output is higher than expected in Figure 1.This may cause wrong judge when use the design to detect miR-21. Some measures will be taken to solve this question. Besides, we are going to endeavor to construct the other networks mentioned in modeling work.