 "
"
Team:TU Darmstadt/Modelling/Statistics
From 2013.igem.org
| (12 intermediate revisions not shown) | |||
| Line 186: | Line 186: | ||
<font size="3" color="#F0F8FF" face="Arial regular"> | <font size="3" color="#F0F8FF" face="Arial regular"> | ||
<p text-aligne:left style="margin-left:50px; margin-right:50px"> | <p text-aligne:left style="margin-left:50px; margin-right:50px"> | ||
| - | |||
| - | In information theory the Kullback-Leibler-Divergence (DKL) describes and quantifies the distance between | + | <font size="5" color="#F0F8FF" face="Arial regular">The DKL Analysis</font> |
| + | <br> | ||
| + | <br> | ||
| + | |||
| + | |||
| + | In information theory the Kullback-Leibler-Divergence (DKL<sup><span style="color:blue">[1]</span></sup>) describes and quantifies the distance between | ||
two distributions P and Q. Where P denotes an experimental distribution, it is compared with Q, a reference distribution. DKL is also known as ‘relative entropy’ as well as ‘mutual information’. | two distributions P and Q. Where P denotes an experimental distribution, it is compared with Q, a reference distribution. DKL is also known as ‘relative entropy’ as well as ‘mutual information’. | ||
Although DKL is often used as a metric or distance measurement, it is not a true measurement because it is not symmetric. | Although DKL is often used as a metric or distance measurement, it is not a true measurement because it is not symmetric. | ||
| + | |||
| + | <br> | ||
| + | <br> | ||
<center> | <center> | ||
<img alt="DKL" src="/wiki/images/7/71/DKL.png" width="555" height="138"> | <img alt="DKL" src="/wiki/images/7/71/DKL.png" width="555" height="138"> | ||
</center> | </center> | ||
| + | |||
<br> | <br> | ||
<br> | <br> | ||
<br> | <br> | ||
| + | <font size="3" color="#F0F8FF" face="Arial regular"> | ||
| + | <p text-aligne:left style="margin-left:50px; margin-right:50px"> | ||
| + | Here, P(i) and Q(i) denote the densities of P and Q at a position i. | ||
| + | In our study, we use the DKL to describe the distances of the survey datasets from the human practice project. | ||
| + | Therefore, we have to calculate a histogram out of the different datasets. Here, it is important to perform a constant binsize. In this approach we assume that a hypothetical distribution Q is uniformly distributed. | ||
| + | To achieve this, we grate an appropriate test data set with the random generator runif in R. | ||
| + | |||
| + | </p></font> | ||
<br> | <br> | ||
| + | <br> | ||
| + | |||
| + | <br> | ||
| + | |||
| + | </body> | ||
| + | |||
| + | |||
| + | |||
| + | |||
| + | <h2><font size="6" color="#F0F8FF" face="Arial regular">Results</font></h2> | ||
| + | |||
<br> | <br> | ||
<br> | <br> | ||
<font size="3" color="#F0F8FF" face="Arial regular"> | <font size="3" color="#F0F8FF" face="Arial regular"> | ||
<p text-aligne:left style="margin-left:50px; margin-right:50px"> | <p text-aligne:left style="margin-left:50px; margin-right:50px"> | ||
| - | + | To validate the significance of our data we gathered in our human practice survey, we computed the DKL between our contestants and an artificial random distribution. High DKL values indicate a significant distribution. | |
| - | + | ||
| - | </p | + | </p> |
<br> | <br> | ||
| + | |||
| + | <center> | ||
| + | |||
| + | <img alt="Test" src="/wiki/images/e/ea/DKL2.png" width="400" height="400"> | ||
| + | |||
<br> | <br> | ||
| + | <font size="3" color="#F0F8FF" face="Arial regular"> | ||
| + | <p text-aligne:left style="margin-left:50px; margin-right:50px"> | ||
| + | |||
<br> | <br> | ||
| + | |||
| + | As can be seen in the graphic above, the DKL concerning our contestants indicate a significant data acquisition. For detailed analysis, see : <a href="https://2013.igem.org/Team:TU_Darmstadt/humanpractice/Results"><font size="3" color="#F0F8FF" face="Arial regular"><b>Human resource / results</b></a> | ||
| + | </p> | ||
<br> | <br> | ||
| + | |||
<center> | <center> | ||
| - | <img alt="Test" src="/wiki/images/ | + | |
| + | <img alt="Test" src="/wiki/images/c/c4/Gender_Produkts.png" width="400" height="400"> | ||
</center> | </center> | ||
| - | </ | + | |
| + | <br> | ||
| + | |||
| + | <font size="3" color="#F0F8FF" face="Arial regular"> | ||
| + | <p text-aligne:left style="margin-left:50px; margin-right:50px"> | ||
| + | |||
| + | If we focus on the general opinion of male vs female contestants regarding basic research, we can observe a similar density distribution among the sexes. However, there seem to be more men, who tend to vote in the extreme end of the scale, with a tendency towards a positive opinion. | ||
| + | </p> | ||
| + | <br> | ||
| + | |||
| + | <center> | ||
| + | |||
| + | <img alt="Test" src="/wiki/images/7/79/XXGender.png" width="400" height="400"> | ||
| + | |||
| + | </center> | ||
| + | |||
| + | <br> | ||
| + | <font size="3" color="#F0F8FF" face="Arial regular"> | ||
| + | <p text-aligne:left style="margin-left:50px; margin-right:50px"> | ||
| + | |||
| + | If correlated to their age, men and women show the same density distribution. | ||
| + | |||
| + | </p> | ||
| + | <br><br><br> | ||
| + | |||
| + | <h2><font size="6" color="#F0F8FF" face="Arial regular">References</font></h2> | ||
| + | |||
| + | <br> | ||
| + | <br> | ||
| + | <ol> | ||
| + | <li style="margin-left:15px; margin-right:50px; text-align:justify">Kullback, S.; Leibler, R.A. (1951) <i>On Information and Sufficiency</i> Annals of Mathematical Statistics 22 (1): 79–86. doi:10.1214/aoms/1177729694. MR 39968.</li> | ||
| + | </ol> | ||
| + | |||
| + | |||
</html> | </html> | ||
Latest revision as of 02:42, 5 October 2013
Information Theory
The DKL Analysis
In information theory the Kullback-Leibler-Divergence (DKL[1]) describes and quantifies the distance between
two distributions P and Q. Where P denotes an experimental distribution, it is compared with Q, a reference distribution. DKL is also known as ‘relative entropy’ as well as ‘mutual information’.
Although DKL is often used as a metric or distance measurement, it is not a true measurement because it is not symmetric.

Here, P(i) and Q(i) denote the densities of P and Q at a position i. In our study, we use the DKL to describe the distances of the survey datasets from the human practice project. Therefore, we have to calculate a histogram out of the different datasets. Here, it is important to perform a constant binsize. In this approach we assume that a hypothetical distribution Q is uniformly distributed. To achieve this, we grate an appropriate test data set with the random generator runif in R.
Results
To validate the significance of our data we gathered in our human practice survey, we computed the DKL between our contestants and an artificial random distribution. High DKL values indicate a significant distribution.
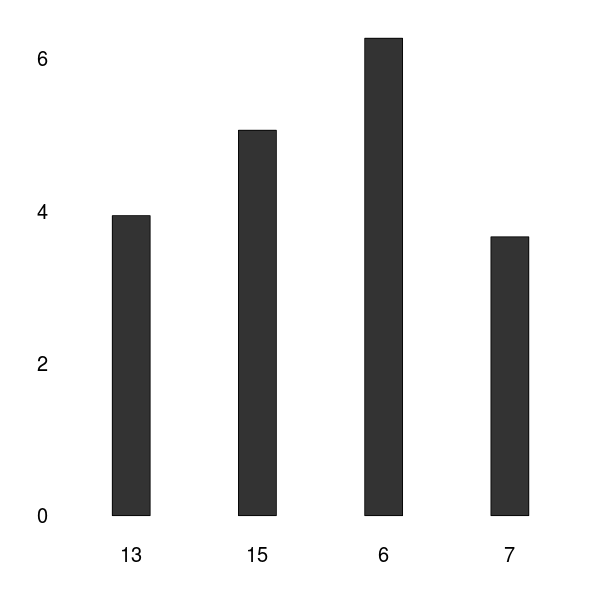
As can be seen in the graphic above, the DKL concerning our contestants indicate a significant data acquisition. For detailed analysis, see : Human resource / results
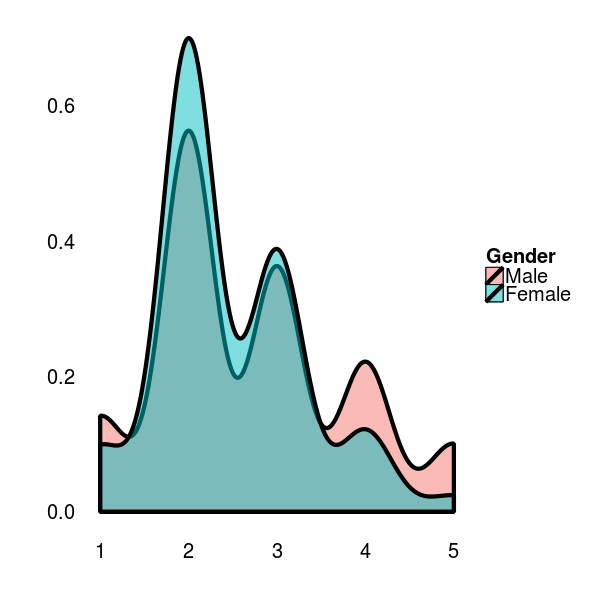
If we focus on the general opinion of male vs female contestants regarding basic research, we can observe a similar density distribution among the sexes. However, there seem to be more men, who tend to vote in the extreme end of the scale, with a tendency towards a positive opinion.

If correlated to their age, men and women show the same density distribution.
References
- Kullback, S.; Leibler, R.A. (1951) On Information and Sufficiency Annals of Mathematical Statistics 22 (1): 79–86. doi:10.1214/aoms/1177729694. MR 39968.