 "
"
Team:XMU Software
From 2013.igem.org
| Line 1: | Line 1: | ||
<!DOCTYPE HTML> | <!DOCTYPE HTML> | ||
<head> | <head> | ||
| + | <META http-equiv="Conten-Type" content="textml;charset=UTF-8"> | ||
<script src="http://ajax.googleapis.com/ajax/libs/jquery/1.8.0/jquery.min.js"></script> | <script src="http://ajax.googleapis.com/ajax/libs/jquery/1.8.0/jquery.min.js"></script> | ||
<script type="text/javascript" async="" src="https://2013.igem.org/wiki/index.php?title=Team:XMU_Software/js&action=raw&ctype=text/javascript"></script> | <script type="text/javascript" async="" src="https://2013.igem.org/wiki/index.php?title=Team:XMU_Software/js&action=raw&ctype=text/javascript"></script> | ||
Revision as of 15:57, 13 September 2013
<!DOCTYPE HTML>
<head>
<META http-equiv="Conten-Type" content="textml;charset=UTF-8">
<script src="http://ajax.googleapis.com/ajax/libs/jquery/1.8.0/jquery.min.js"></script> <script type="text/javascript" async="" src="https://2013.igem.org/wiki/index.php?title=Team:XMU_Software/js&action=raw&ctype=text/javascript"></script> <link rel="stylesheet" type="text/css" href="https://2013.igem.org/wiki/index.php?title=Team:XMU_Software/css&action=raw&ctype=text/css"/>
</head>
<body>
- <a href="#">Home</a>
- <a href="#">Team</a>
- <a href="#_ourteam">Our Team</a>
- <a href="#_acknowledgement">Acknowledgement</a>
- <a href="#_city">Our City&University </a>
- <a href="#">Project</a>
- <a href="#">Promoter-decoder</a>
- <a href="#">RBS-decoder</a>
- <a href="#">Terminator</a>
- <a href="#">SynoProteiner</a>
- <a href="#">E'Note</a>
- <a href="#">Safetyform</a>
- <a href="#_basicsafety">Basic Safety</a>
- <a href="#_softwaresatety">Software Division</a>
- <a href="#">Outreach</a>
- <a href="#_exchange">Exchange</a>
- <a href="#_lectures">Lectures</a>
- <a href="#_gardenparty">Themed Garden Party</a>
- <a href="#_doodles">Painting</a>
- <a href="#">Notebook</a>
- <a href="#_tool">Tools</a>
- <a href="#_journal">Journal</a>
      
<a href="https://2013.igem.org/Main_Page" target="_blank" ><img src=" " width="80px" height="60px"></a>
" width="80px" height="60px"></a>
- <a href="" target="_blank">
<img alt="" src="
 " /></a>
" /></a> - <a href="" target="_blank">
<img alt="" src="
 " /></a>
" /></a> - <a href="" target="_blank">
<img alt="" src="
 " /></a>
" /></a> - <a href="" target="_blank">
<img alt="" src="
 " /></a>
" /></a> - <a href="" target="_blank">
<img alt="" src="
 " /></a>
" /></a>
<img src=" " ></br>
<img src="
" ></br>
<img src=" " class="home_s3p1"></br>
<img src="
" class="home_s3p1"></br>
<img src=" " class="home_s3p1" onClick="safety();"></br>
<img src="
" class="home_s3p1" onClick="safety();"></br>
<img src=" " class="home_s3p1" onClick="hp();"></br>
<img src="
" class="home_s3p1" onClick="hp();"></br>
<img src=" " class="home_s3p1">
" class="home_s3p1">
<img src=" " width="120px" height="120px">
<img src="
" width="120px" height="120px">
<img src=" " width="120px" height="120px">
<img src="
" width="120px" height="120px">
<img src=" " width="120px" height="120px">
<img src="
" width="120px" height="120px">
<img src=" " width="120px" height="120px">
<img src="
" width="120px" height="120px">
<img src=" " width="120px" height="120px">
<img src="
" width="120px" height="120px">
<img src=" " width="120px" height="120px">
" width="120px" height="120px">
<img src=" " width="1348px">
" width="1348px">
<img src=" " width="1348px" class="sep_photo">
" width="1348px" class="sep_photo">
 " >
" > " >
" > " >
" > " >
" > " >
" > " >
" > " >
" > " >
" > " >
" > " >
" > " >
" > " >
" > " >
" > " >
" > " >
" > " >
" > " >
" > " >
" > " >
" > " >
" > " >
" > " >
" > ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
">Prof. Bai-shan Fang</br></br> Dr. Bai-shan Fang is the professor in College of Chemistry & Chemical Engineering at Xiamen University. In the group of biocatalysis and biotransformation, his research mainly focuses on synthetic biology, mining and the transformation of the enzyme, construction of bio-molecular machines, the application of new biocatalysts. His major role of XMU iGEM team is to mentor for all and to enlighten the members. </br> </br></br> </br></br> </br></br>
 ">
">Associate Prof. I-Son Ng</br></br> Dr. I-Son Ng is the associate professor in College of Chemistry & Chemical Engineering at Xiamen University. Her research interests are biofuel, engineering of enzyme and protein, zymology, genetic engineering, biochemical separation procedures and proteomics. Her role for the project is to provide suggestions and instruments.</br> </br></br> </br></br> </br></br>
 ">
">Ruosang Qiu</br></br> It is great for a team to have an omniscient advisor, even better an inspiring one. Ruosang Qiu , our beloved advisor, definitely is offering both. Her hard work as well as undoubted adorable personality is the motivation of our team members’ efforts, her clear mind combined with provident planning lays the foundation of our successful project, To quote her words: I’ was a happy iGEMer in 2012, I’m going to make you all happy iGEMers in 2013.</br></br> </br></br> </br></br>
 ">
">Xin Wu</br></br> The past three years have seen his tremendous dedication to iGEM, Xin Wu, a passionate team member in XMU-China-2011, a devoted team leader in XMU-China-2012 and now, an invaluable advisor in XMU-Software-2013. Had it not been Xin Wu's constant encouragement and guidance, we,the inexperienced iGEMers might have been faint-hearted and failed to face up to the challenges during the process. It is drawing on his expertise in synthetic biology and proficiency in iGEM competition that we have solved the seemingly unsolvable and conquered the seemingly unconquerable.</br></br></br></br></br>
 ">
">Youbin Mo</br></br> Youbin Mo is one of the great advisors of XMU software team in 2013. As a computational biophysicist, y, he is an unquestionable master of biological model and computer programing. In the meanwhile, website constructing is also Mo’s technical ability which he acquired by participating the iGEM last year. Youbin gives play to his talent by teaching fundamental program skills to new iGEMers as well as directing them to be self-reliant synthetic biologists.</br></br> </br></br> </br></br>
<img src="" width="1348px" class="sep_photo">
All work described on this wiki or on our parts registry pages was done by iGEM Team XMU-China 2012. We managed the whole project, from planning to financing the complete lab work by ourselves. Nevertheless we could not have done all this work without the help, advice and guidance of several people. Therefore, special thanks to the following people:</br> Our advisor Graduate Xuesong Zheng for helping us in fluorescence test and immobilization.</br> Prof. Xiaodong Chen for providing us many instruments such as ELISA reader to test the fluorescence and his students Song Huang, Renpan Deng, Xiang You for experimental guidance.</br> Prof. Yinghua Lu and his student Shiduo Zhang for helping us make the PDMDAAC-NaCS microcapsules.</br> Dr. Ying Zeng, Kunming Institute of Botany, Chinese Academy of Sciences, who has provided us with valuable guidance in constructing gene circuits.</br> </br></br>
<img src="" width="1348px" class="sep_photo">
Xiamen</br></br> Xiamen, also known as Amoy to the west, is a cozy city located in the southeastern part of China, and has a relaxing coastal charm with a population of 1.3 million. It's a historical harbor city which was founded in the mid-14 century, in the early years of the Ming Dynasty. In the early 1980's, Xiamen was declared as one of China's first Special Economic Zone, taking advantages of the city's heritage as a trading center and the proximity to Taiwan. In 2004 the city won the finals of the world's Human Settlements and Environment Award, "Nations in Bloom". Xiamen is one of China's most attractive and best-maintained resort city, and attracts a large number of foreign and local tourists. The city is easily accessible by air, and there are direct flights from Hong Kong, Kuala Lumpur, Osaka, Seoul, Singapore and Tokyo. Within China, Xiamen airport is linked to more than 30 domestic airports.
<img src=" ">
">
<img src=" ">
">
Xiamen University</br></br> Xiamen University (XMU), also known as Universitas Amoiensis in Latin, is one of the top universities in China. It was founded in 1921 by Tan Kah-Kee, the well-known patriotic overseas Chinese leader. As an integrated university, XMU owns a comprehensive branches of discipline as well as many specialized institutes. Economy, counting, chemistry, life science and marine science all win high fame nationwide and even worldwide. The main campus of XMU locates in a picturesque setting between the sea and a scenic mountain, spreading over 150 hectares, and is generally regarded as the most beautiful campus in China.
<img src="" width="1348px">
<img src="" width="1348px" class="sep_photo">
</br></br>
</br>
</br>
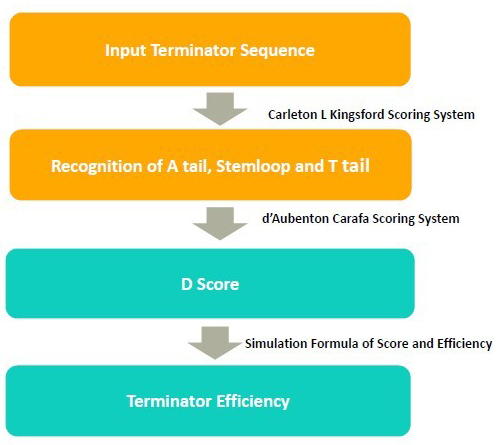 ">
"></br>
 ">
"> ">
"> ">
"></br>
 ">
"></br>
</br></br></br></br></br></br></br></br>
<img src="" width="1348px" class="sep_photo">
</br></br>
</br>
</br>
 ">
"></br>
 ">
"></br>
 ">
"></br>
</br>
</br></br></br></br></br></br></br></br>
<img src="" width="1348px" class="sep_photo">
</br></br>
</br>
 ">
"> "><img src="
"><img src=" ">
"> ">
"> ">
"> ">
"></br>
</br>
 ">
"> "><img src="
"><img src=" ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"></br>
</br>
</br>
</br>
</br></br></br></br></br></br></br></br>
<img src="" width="1348px" class="sep_photo">
</br></br>
</br>
</br>
</br>
 ">
"> ">
"> "> is the target ratio of k-th codon, <img src="
"> is the target ratio of k-th codon, <img src=" "> is the actual ratio of k-th codon in the sequence,the best value of cpi is 0.2 in the software.
"> is the actual ratio of k-th codon in the sequence,the best value of cpi is 0.2 in the software. ">
"> ">
"> ">
"> ">stands for the ratio of single codon ckin the complete genome'<img src="
">stands for the ratio of single codon ckin the complete genome'<img src=" ">is the number of pair (ci,cj) in high-expression genes,and high-expression genes are genes whose copy numbers of mRNA can be detected at least 20 per cell.
">is the number of pair (ci,cj) in high-expression genes,and high-expression genes are genes whose copy numbers of mRNA can be detected at least 20 per cell.  ">
"> ">equals to the number of amino acid encoded by ci in the whole protein set.
">equals to the number of amino acid encoded by ci in the whole protein set.  ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> ">
"> "> and <img src="
"> and <img src=" "> , the domination status can be evaluated as follows:
"> , the domination status can be evaluated as follows: "> ><img src="
"> ><img src=" "> and <img src="
"> and <img src=" "> >=<img src="
"> >=<img src=" "> , sequence 1 dominates sequence 2."> >=<img src=""> and <img src=""> ><img src=""> , sequence 1 dominates sequence 2."><<img src=""> and <img src=""> <=<img src=""> , sequence 2 dominates sequence 1."> <=<img src=""> and <img src=""> <<img src=""> , sequence 2 dominates sequence 1.
"> , sequence 1 dominates sequence 2."> >=<img src=""> and <img src=""> ><img src=""> , sequence 1 dominates sequence 2."><<img src=""> and <img src=""> <=<img src=""> , sequence 2 dominates sequence 1."> <=<img src=""> and <img src=""> <<img src=""> , sequence 2 dominates sequence 1.</br>
</br>
</br></br></br></br></br></br></br></br>
<img src="" width="1348px" >
<a name="_basicsafety" id="_basicsafety"></a>
| Part number. | Where did you get the physical DNA for this part (which lab, synthesis company, etc) | What species does this part originally come from? | What is the Risk Group of the species? | What is the function of this part,in its parent species ? | |
| Ex | BBa_C0040 | Synthesized, Blue Heron | Acinetobacter baumannii | 2 | Confers tetracycline resistance |
| 1 | BBa_K1070000 | PCR, Dr.Baishan Fang's lab, Xiamen University | Registry of Standard Biological Parts | 1 | The promoter induced by arabinose |
| 2 | BBa_K1070001 | PCR, Dr.Baishan Fang's lab, Xiamen University | Registry of Standard Biological Parts | 1 | The promoter induced by arabinose |
| 3 | BBa_K1070002 | PCR, Dr.Baishan Fang's lab, Xiamen University | Registry of Standard Biological Parts | 1 | The promoter induced by arabinose |
| 4 | BBa_K1070003 | PCR, Dr.Baishan Fang's lab, Xiamen University | Registry of Standard Biological Parts | 1 | The promoter induced by arabinose |
| Species | Strain no/name | Risk Group | Risk group source link | Disease risk to humans? If so, which disease? | |
| Ex | E.coli(K 12) | NEB 10 Beta | 1 | www.absa.org/riskgroups/bacteria search.php?genus=&species=coli | Yes. May cause irritation to skin, eyes, and respiratory tract, may affect kidneys. |
| 1 | E.coli(K 12) | DH5α | 1 | http://www.absa.org/riskgroups/bacteriasearch.php?genus=Escherichia | Yes. May cause irritation to skin, eyes, and respiratory tract, may affect kidneys. |
| 2 | E.coli(B) | BL21 | 1 | http://www.absa.org/riskgroups/bacteriasearch.php?genus=Escherichia | Yes. May cause irritation to skin, eyes, and respiratory tract, may affect kidneys. |
</br>
</br>
</br>
</br>
</br>
</br></br></br>
<a name="_softwaresatety" id="_softwaresatety"></a>
</br>
</br>
</br>
</br>
</br>
</br> </br></br></br></br></br></br>
<img src="" width="1348px">
<a name="_exchange" id="_exchange"></a>
 "><img src="
"><img src=" ">
"> "><img src="
"><img src=" ">
"> "><img src="
"><img src=" ">
"></br></br></br>
<a name="_lectures" id="_lectures"></a>
 "><img src="
"><img src=" ">
"> "><img src="
"><img src=" ">
"></br></br></br>
<a name="_gardenparty" id="_gardenparty"></a>
 "><img src="
"><img src=" ">
"> "><img src="
"><img src=" ">
"> "><img src="
"><img src=" ">
"></br></br></br>
<a name="_doodles" id="_doodles"></a>
 ">
"></br></br></br></br></br></br></br></br></br></br>
<img src="" width="1348px">
<img src="" width="1348px" class="sep_photo">
 " class="notebook_s2m2p1" onmouseover="notebook_s2m2c1();" onmouseout="notebook_s2m2c2();">
" class="notebook_s2m2p1" onmouseover="notebook_s2m2c1();" onmouseout="notebook_s2m2c2();"> " class="notebook_s2m2p1" onmouseover="notebook_s2m2c3();" onmouseout="notebook_s2m2c4();">
" class="notebook_s2m2p1" onmouseover="notebook_s2m2c3();" onmouseout="notebook_s2m2c4();"> " class="notebook_s2m2p1" onmouseover="notebook_s2m2c5();" onmouseout="notebook_s2m2c6();">
" class="notebook_s2m2p1" onmouseover="notebook_s2m2c5();" onmouseout="notebook_s2m2c6();"> <img src="" width="1348px" class="sep_photo">
<img src=" ">
">
</br></br>
<img src="">
</br></br>
</br></br>
</br></br></br></br></br></br>
</br></br></br></br></br></br></br>
<img src="">
</br></br></br></br></br></br></br></br></br></br></br></br>
</br></br></br></br></br></br></br></br>
</br></br></br></br></br></br></br>
</br></br>
<img src="">
</br></br></br></br></br></br></br>
</br></br></br></br></br></br></br></br></br></br></br></br></br></br></br>
</br></br></br></br></br></br></br></br></br></br></br></br></br></br></br>
</br></br>
</br></br></br></br>
<img src="">
</br></br>
</br></br></br></br></br></br>
</br></br></br></br></br>
</br></br></br></br>
<img src="">
</br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br>
</br></br></br>
<img src="">
</br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br>
</br></br></br>
<img src="">
</br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br></br>
</br></br></br>
<script> //定位1366*768 var x = window.innerWidth-1366; if(x>0){ x = x / 2; document.getElementById("xmu-software").style.left= x+"px"; } else{ document.getElementById("xmu-software").style.left="0px"; } color1=$("#notebook_s3p2").css("background-color"); color2=$("#notebook_s3p3").css("background-color"); </script> </body>